
Concurrent Inc. today announces the finalization of $10M in Series B funding in a round led by new investor Bain Capital Ventures, with additional participation from existing investors Rembrandt Ventures and True Ventures. Salil Deshpande, Managing Director of Bain Capital Ventures, will join Concurrent Inc.’s board of directors as a result of today’s funding raise. The funding will be used to accelerate the development of Concurrent’s commercial product Driven as well as Cascading, the framework for developing and managing Big Data applications. Driven fills a critical void within the Big Data industry by providing customers with visibility regarding application performance on Hadoop while Cascading represents one of the most widely used frameworks for application development on Hadoop. Concurrent’s Series B funding raise comes hot on the heels of its elaboration of details regarding Cascading 3.0 and the announcement of partnerships with Hadoop vendor Hortonworks and Databricks. Scheduled for release in the early summer, Cascading 3.0 features support for technology platforms and computational frameworks such as local in-memory, Apache MapReduce and Apache Tez. Meanwhile, Cascading’s partnership with Hortonworks integrates the Cascading SDK into the Hortonworks Data Platform under the terms of an agreement whereby Hortonworks will certify, deliver and support the Cascading framework. Today’s funding raise provides further validation of Concurrent’s business model and empowers it to consolidate its early positioning as a leader in the Big Data space, with specializations in applications that streamline and simplify Hadoop application development and cluster management. With its new round of funding in hand, the industry expect Concurrent Inc. to obtain more traction around its flagship product Driven as it continues to innovate at the forefront of technology platforms that facilitate the effective operationalization of Big Data. Today’s Series B announcement brings the total capital raised by Concurrent Inc. to $14M by building upon a March 2013 Series A round of $4M.
Category: Big Data
Trifacta Raises $25M For Big Data Transformation Platform That Enhances Analyst Productivity
Trifacta, the data transformation company, today announced the finalization of $25M in Series C funding. The funding round was led by a new investor, Ignition Partners, with additional participation from existing investors Greylock Partners and Accel Partners. As a result of the investment, Frank Artale, Managing Director of Ignition Partners, will join the Trifacta board of directors. The Trifacta Data Transformation Platform enhances the productivity of data analysts and scientists by transforming Big Data into a structure that renders it easier to analyze, visualize and manipulate. The Trifacta platform’s predictive interaction technology allows users to visualize Big Data, interact with different data visualizations and take advantage of machine-learning based predictions regarding data transformations and analytics of interest. The platform aims to deliver transparency regarding the data in question, agility with respect to the user’s ability to interact with Big Data, predictive intelligence based on machine learning about the efficacy of user interactions with data and scalability marked by the ability to interact with large, heterogeneous datasets. As told to Cloud Computing Today by Trifacta CEO Joe Hellerstein, Trifacta customers can take advantage of the platform’s ability to cleanse and organize Big Data in conjunction with other enterprise software platforms such as SAS, for example. That said, Trifacta itself offers its own universe of tools for facilitating insights with respect to Big Data and, unlike many business intelligence or analytics platforms, is designed specifically for the purpose of transformation, data discovery and visualization of massive datasets. Today’s announcement about Trifacta’s Series C funding comes hot on the heels of a March 2014 partnership with Cloudera to jointly deliver the Trifacta Data Transformation platform in conjunction with Cloudera’s Hadoop distribution. To date, Trifacta has raised a total of approximately $45M in funding. Given partnerships such as Cloudera in hand, and $25M in Series C funding that comes roughly 6 months after its Series B capital raise of $12M, the industry should expect Trifacta’s traction amongst Big Data customers to skyrocket as news about its ability to transform Big Data into a usable form that accelerates the development of actionable business intelligence proliferates.
BMC Hadoop Management Product Supports Hortonworks Data Platform
BMC Software and Hortonworks recently announced a partnership whereby BMC’s Control-M for Hadoop platform now supports the Hortonworks Data Platform. The BMC Control-M for Hadoop platform streamlines the creation of Big Data workflows, automates Hadoop batch processing and accelerates Hadoop integration into a pre-existing data infrastructure. The partnership between BMC Software and Hortonworks puts BMC’s weight squarely behind the Hortonworks Data Platform while concomitantly highlighting the Big Data management capabilities of the BMC Control-M for Hadoop data management platform. As such, the collaboration serves to extend adoption of the Hortonworks Hadoop distribution to BMC’s customers in addition to giving BMC the credibility associated with a technology partnership with one of the industry’s premier Hadoop vendors. Tuesday’s announcement underscores the rising fortunes of Hortonworks, which recently completed the acquisition of XA Secure with a view to delivering a comprehensive Hadoop security solution that it plans to open source in the latter half of 2014. Meanwhile, the BMC-Hortonworks partnership additionally emphasizes the emerging market for Big Data management platforms that simplify or streamline the development and management of Hadoop applications and datasets.
MapR Reports Impressive Growth For Q1 2014 Amidst Fierce Competition From Hortonworks and Cloudera
Hadoop vendor MapR recently reported record growth marked by a threefold increase in Q1 2014 bookings as compared to Q1 2013. MapR’s announcement of impressive growth comes in conjunction with recent news of its integration with the HP Vertica platform, support for Apache Hadoop 2.x and YARN, as well as support for all five components of Apache Spark in its Hadoop distribution. MapR additionally noted that it now claims customers from the financial services, networking/computers, software, online/web, ad media, telecom and market research verticals that have spent more than $1M on MapR products, in addition to one customer that has generated over a billion dollars of revenue that can be attributed to the usage of MapR’s technology. The announcement of MapR’s impressive Q1 growth is particularly notable given the hefty capital raises finalized by competitors Hortonworks and Cloudera on the order of $100M and $900M respectively within the last two months. As the battle for Hadoop market share shakes out, MapR will also need to contend with the implications of the nascent partnership between Cloudera and NoSQL market leader MongoDB.
Cascading 3.0 Adds Support For Wide Range Of Computational Frameworks And Data Fabrics
Today, Concurrent, Inc. announces the release of Cascading 3.0, the latest version of the popular open source framework for developing and managing Big Data applications. Widely recognized as the de facto framework for the development of Big Data applications on platforms such as Apache Hadoop, Cascading simplifies application development by means of an abstraction framework that facilitates the execution and orchestration of jobs and processes. Compatible with all major Hadoop distributions, Cascading sits squarely at the heart of the Big Data revolution by streamlining the operationalization of Big Data applications in conjunction with Driven, a commercial product from Concurrent that provides visibility regarding application performance within a Hadoop cluster.
Today’s announcement extends Cascading to platforms and computational frameworks such as local in-memory, Apache MapReduce and Apache Tez. Going forward, Concurrent plans for Cascading 3.0 to ship with support for Apache Spark, Apache Storm and other computational frameworks by means of its customizable query planner, which allows customers to extend the operation of Cascading to compatible computational fabrics as illustrated below:
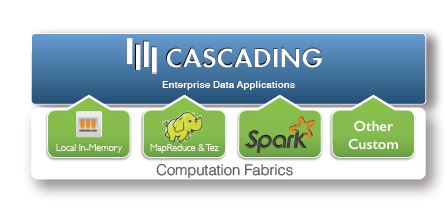
The breakthrough represented by today’s announcement is that it renders Cascading extensible to a variety of computational frameworks and data fabrics and thereby expands the range of use cases and environments in which Cascading can be optimally used. Moreover, the customizable query planner featured in today’s release allows customers to configure their Cascading deployment to operate in conjunction with emerging technologies and data fabrics that can now be integrated into a Cascading deployment by means of the functionality represented in Cascading 3.0.
Used by companies such as Twitter, eBay, FourSquare, Etsy and The Climate Corporation, Cascading boasts over 150,000 applications a month, more than 7,000 deployments and 10% month over month growth in downloads. The release of Cascading 3.0 builds on Concurrent’s recent partnership with Hortonworks whereby Cascading will be integrated into the Hortonworks Data Platform and Hortonworks will certify and support the delivery of Cascading in conjunction with its Hadoop distribution. Concurrent, Inc. also recently revealed details of a strategic partnership with Databricks, the principal steward behind the Apache Spark project, that allows it to “operate over Spark…[the] next generation Big Data processing engine that supports batch, interactive and streaming workloads at scale.” In an interview with Cloud Computing Today, Concurrent CEO Gary Nakamura confirmed that Concurrent plans to negotiate partnerships analogous to the agreement with Hortonworks with other Hadoop distribution vendors in order to ensure that Cascading consolidates its positioning as the framework of choice for the development of Big Data applications. Overall, the release of Cascading 3.0 represents a critical product enhancement that positions Cascading to operate over a broader pasture of computational frameworks and consequently assert its relevance for Big Data application development in a variety of data and computational frameworks. More importantly, however, the product enhancement in Cascading 3.0, in conjunction with the partnership with Databricks regarding Apache Spark, suggests that Cascading is well on its way to becoming the universal framework of choice for developing and managing applications in a Big Data environment, particularly given its compatibility with a wide range of Hadoop distributions and data and computational frameworks.
PepperData Raises $5M For Enhanced Application Performance On Hadoop
PepperData, a San Francisco-based Big Data startup, recently announced the finalization of $5M in Series A funding in a round led Signia Venture Partners and the Webb Investment Network. The funding will be used to accelerate the company’s product development as well as to expand its sales and marketing operations. Led by former executives from Microsoft and Yahoo, PepperData specializes in enhancing the ability of Hadoop clusters to run multiple applications concurrently. The PepperData platform addresses the problem whereby Hadoop clusters that contain more than one application run the risk of allowing one job or application to monopolize the cluster. PepperData’s technology optimizes application performance within a Hadoop cluster by monitoring resource usage across applications and recalibrating resource allocations to ensure that jobs complete in a timely fashion. As such, PepperData enables more effective utilization of resources, enhanced performance for Hadoop-based applications and increased visibility regarding application performance in a Hadoop cluster.

You must be logged in to post a comment.