
Cloudmeter today announces the general availability of Cloudmeter Stream, a non-invasive platform that enables customers to transform Big Data streams of network data into actionable business intelligence. Cloudmeter also announces the early access availability of Cloudmeter Insight, a SaaS application that integrates back-end network analytics with front-end marketing analytics to deliver integrated data regarding user experiences of application platforms. Together, Cloudmeter Stream and Cloudmeter Insight expand the purview of Big Data analytics to network data and enable customers to obtain a 360 degree view of user interactions with their products. Both Cloudmeter Stream and Cloudmeter Insight allow access to network data without risks of physical disruption to network infrastructures.
Cloudmeter’s analytics represent an extension of the DevOps movement by allowing operations to more effectively understand the impact of IT infrastructure on end-user experiences. Application owners can use Cloudmeter to effectively configure business rules to determine which network data attributes constitute fields of interest. For example, customers can create business rules that identify session errors, network traffic on specific servers or data regarding the elapsed time between specific interactions with the platform. Users create business rules and manage the application more generally using an intuitive user interface featuring screens such as the following:
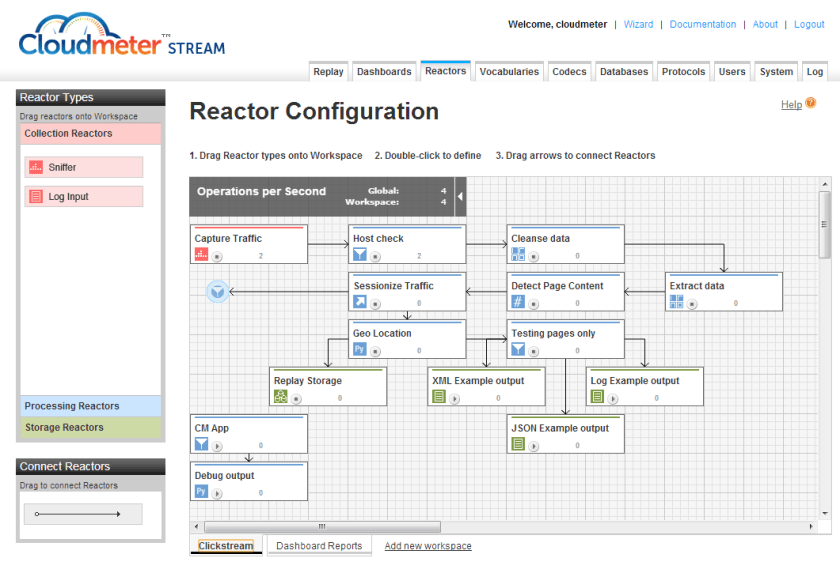
Cloudmeter CEO Mike Dickey remarked on the innovation represented by the platform for capturing network data by noting:
Our new data capture technology is a culmination of many years of experience building network-based data capture products. It enables customers to gain real time access into the wealth of business and IT information without the need to connect to physical network infrastructure, and without introducing risk to production systems or application performance.
Dickey underscores how Cloudmeter’s technology brings the Big Data revolution to network data and concomitantly empowers customers to access “business and IT information” in ways that have the potential to transform both their marketing platforms as well as their IT infrastructure design. In an interview with Cloud Computing Today, Cloudmeter’s COO Ronit Belson remarked that, rather than falling into the category of DevOps products, the company’s platform more appropriately represents a disruptive innovation in the MarkOps space defined by the integration of marketing-related front-end application design with the Operations-related design of their platform’s IT infrastructure. Cloudmeter Stream integrates with Big Data platforms such as Splunk and GoodData allowing users to integrate petabytes of machine data with data selectively culled from the business rules specific to Cloudmeter’s user interface.
Cloudmeter Stream is complemented by Cloudmeter Insight, a SaaS application that transforms data captured by Cloudmeter Insight into visual representations that allow application owners to comprehensively understand end-user experiences of an application as represented below:

Cloudmeter Stream leverages widgets to allow users to customize reports and dashboards of their choosing. The result is an integrated view of an application’s backend and front-end user experience in ways that allow application owners to obtain a truly holistic picture of user experiences with their platforms. Today’s announcements point toward two exciting new releases into the application performance management space as Big Data begins to own up to its potential of delivering 360 degree views of user experiences with technology platforms. Cloudmeter’s customer base includes Netflix, SAP and Saks Fifth Avenue and 1-800-Flowers.



You must be logged in to post a comment.