
Palo Alto-based Minio recently announced the general availability of an object storage server designed for cloud-based environments. Minio empowers developers to store unstructured data in private and public cloud environments using a distributed object storage server featuring erasure code and bitrot detection capabilities. Minio’s ability to store massive volumes of unstructured data gives developers access to object storage with functionality analogous to Amazon S3 that can be extended to other cloud providers such as Digital Ocean and Packet. The platform boasts compatibility with Amazon S3, advanced data protection functionality and support for Lambda functions that automate the execution of scripts that operate on incoming or existing datasets. Available under an Apache version 2.0 license, Minio has been embraced by open source communities such as Mesos, Docker and Kubernetes that recognize its product differentiation as represented by its open source cloud-native architecture and streamlined deployment functionality. The company’s open source object storage platform claims over 125K code contributions and widespread deployment as a Docker container. The announcement of Minio’s general availability as a distributed object storage server marks a milestone in its evolution that builds upon its early adoption success and emergence as a key player in the cloud-native object storage space. Expect Minio’s adoption to continue expanding, particularly in light of its general availability announcement and deepening specialization in the delivery of cloud-native object storage solutions for massive quantities of unstructured data.
Tag: big data
Q&A With Jon Gacek, CEO Of Quantum, On The Rise Of Corporate Video Usage And The Storage Industry
Cloud Computing Today recently spoke with Jon Gacek, CEO of Quantum, about the demands that the proliferation of video-based data imposes on the storage needs of Quantum’s customers. As noted below, Mr. Gacek elaborated on the way in which increasing volumes of video-based data creates special challenges for customers that are driving them to seek storage solutions with the performance, scalability, data retention, automation and indexing capabilities specific to Quantum and its partners.
Cloud Computing Today Question #1: How do you envision the effect of trends in the usage of IP video traffic on the storage industry?
Jon Gacek, (CEO, Quantum) Response #1: The increasing amount of video is creating greater storage demands, including the need to ingest larger files at high speeds, to retain that data cost effectively for long periods of time and to ensure the data can be easily accessed and shared for collaboration, analysis and re-monetization or other reuse. All of this creates new opportunities for the storage industry to help customers. However, as video transitions from HD to 4K and even higher resolutions, general-purpose storage companies are finding it increasingly difficult to meet the performance demands associated with storing and managing such data. As a result, customers are turning to storage providers like Quantum that can offer specialized solutions optimized for video workflows.
Cloud Computing Today Question #2: What challenges does the storage industry face in relation to the rise of corporate video?
Jon Gacek, (CEO, Quantum) Response #2: As is the case with video, generally, the rise of corporate video creates new data storage and management challenges for customers and opportunities for specialized storage providers to help them meet those challenges. A key element of this is understanding that the customer looking for a corporate video solution often isn’t in IT. For example, it may be a marketing leader trying to leverage video assets across multiple platforms and channels to drive greater brand awareness or promote a new product. They don’t have time to become a video storage expert, but they also want to maintain control of their video rather than depend on an already over-burdened IT department. This means they want solutions that are easy to use, include a high level of automation and cost as little as possible. And it’s this cost factor that makes the ability to offer tiered storage solutions such a differentiator in the storage industry. Moving video data off expensive primary storage to lower-cost disk, object storage, tape or cloud tiers can result in significant savings. At the same time, it’s critical that the storage system be able to keep track of where that data resides and provide ready access to it when needed.
Cloud Computing Today Question #3: How will the storage industry tackle the problem of indexing unstructured data (such as a notable moment within a soccer video that might be untagged because it is unrelated to a goal, for example)?
Jon Gacek, (CEO, Quantum) Response #3: It’s definitely true that being able to add structure to unstructured data through analytics and indexing enables you to get much greater value out of your data. In the video space, there are a number of companies that provide such capabilities. In fact, we have a partner with some great technology that provides high-speed automated video and image search. You identify the image or kind of shot you’re looking for, and the system can search through massive amounts of data incredibly fast to deliver the results – hours of video can be searched in minutes. This has a wide range of applications, from the sports video example you referenced to government intelligence and counterterrorism to video surveillance. Video surveillance is also a good example of how technology is enabling benefits beyond those originally envisioned for crime prevention and prosecution. For example, municipalities are now using it to monitor and analyze activities at ports to identify ways to increase logistics efficiencies, and retailers are analyzing the data they get from in-store cameras to understand shopping patterns and how the placement of goods can be optimized to increase sales and bolster customer retention. However, none of this is possible unless you have the underlying storage infrastructure that can handle the special demands of managing, preserving and delivering video data.
BigPanda Emerges From Stealth To Manage Deluge Of IT Alerts And Notifications
BigPanda today launches from stealth to tackle the problem of managing the explosion of alerts and notifications that IT administrators increasingly receive, daily, from myriads of applications and devices. The Mountain View-based startup integrates alerts and notifications from disparate sources into a consolidated data feed that parses unstructured data into structured data to create an aggregated alerts and notifications data repository. BigPanda’s proprietary analytics subsequently run against the integrated data repository to enable the creation of topologies and relationships, time-based analytics and statistical analytics as indicated by the screenshot of an incident dashboard below:
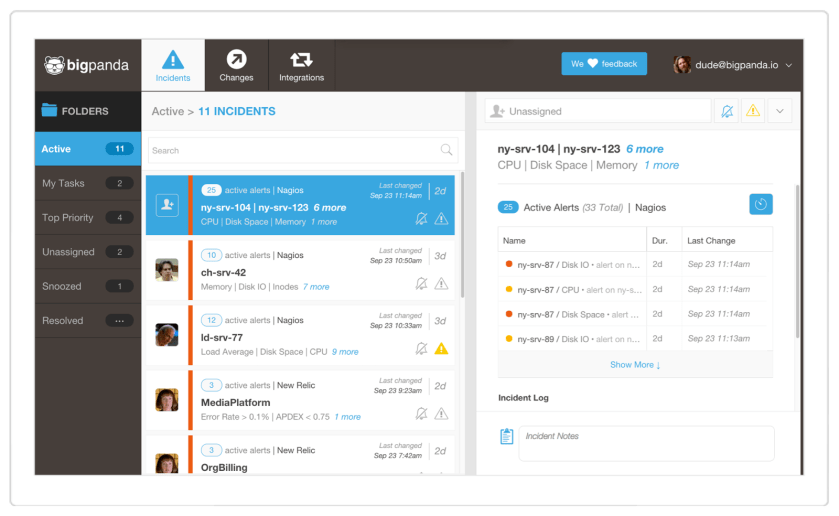
Examples of statistical analytics include probabilistic determinations that the concurrent appearance of notification A, B and C is likely to lead to outcome X as suggested by historical data about the conjunction of the notifications in question. The platform’s machine-learning technology incrementally refines its analytics in relation to incoming data and thereby iteratively delivers more nuanced analyses and visualizations of notifications-related data. Overall, the platform enables customers to more effectively manage the tidal wave of data from notifications that bombard the inboxes of IT administrators by facilitating the derivation of actionable business intelligence based on the aggregation of notifications from discrete systems and applications.
As told to Cloud Computing Today by BigPanda CEO Assaf Resnick, the platform integrates with monitoring systems such as New Relic, Nagios and Splunk and additionally provides REST API functionality to connect to different applications, deployment infrastructures and ITSM tools. Moreover, BigPanda today announces the finalization of $7M in Series A funding in a round led by Mayfield with additional participation from Sequoia Capital. The $7M funding raise brings the total capital raised by BigPanda to $8.5M, following upon a $1.5M pre-Series A seed round of funding from Sequoia Capital. Deployed as a SaaS application that runs on AWS infrastructure while leveraging a MongoDB NoSQL datastore, BigPanda fills a critical niche in the IT management space by delivering one of the few applications aimed at consolidated notification management and analytics. As applications, infrastructure components and networking devices proliferate with dizzying complexity in the contemporary datacenter, platforms like BigPanda are likely to morph into necessary components of IT management as a means of taming the deluge of notifications produced by disparate systems. Meanwhile, BigPanda’s early positioning in the notification-management space renders it a thought leader as well as a technology standout.
Base Enhances Sales Productivity Platform With Real-Time Analytics And Rich Data Visualization
Base, the CRM that leverages real-time data and analytics, recently announced the release of a bevy of new features and functionality that brings real-time, Big Data analytics to cloud-based sales productivity management. Base’s proprietary technology aggregates data from sources such as phone calls, in person meetings, social network-based prospects and news feeds and subsequently produces real-time notifications to sales professionals. As a result, sales teams can minimize their manual input of sales-related data and instead take advantage of the analytic and data visualization capabilities of the Base platform. The Base platform testifies to a qualitative shift within the CRM space marked by the delivery of enhanced automation to sales operations workflows resulting from the conjunction of real-time data, predictive analytics and data visualization. Uzi Shmilovici, CEO of Base, remarked on the positioning of Base within the larger CRM landscape as follows:
Base picks up where other CRMs have left off. Until now, legacy cloud Sales and CRM products like Salesforce have been accepted as ‘the norm’ by the enterprise market. However, recent advancements in big data, mobility and real-time computing reveal a need for a new generation of intelligent sales software that offers flexibility, visibility, and real-time functionality. If you’re using outdated technology that cannot adapt to the advanced needs of modern day sales teams, your competition will crush you.
Here, Shmilovici comments on the way in which big data, real-time analytics and the proliferation of mobile devices have precipitated the creation of a new class of sales applications that outstrip the functionality of “legacy cloud Sales and CRM products like Salesforce.” In a phone interview with Cloud Computing Today, Shmilovici elaborated on the ability of the Base platform to aggregate disparate data sources to produce rich, multivalent profiles of sales prospects that augment the ability of sales teams to convert leads into qualified sales. Base’s ability to enhance sales operations by means of data-driven analytics are illustrated by the screenshot below:

The graphic above illustrates the platform’s ability to track sales conversions at the level of individual sales professionals as well as sales managers or owners within a team. VPs of Sales can customize analytics regarding the progress of their teams to enable enhanced talent and performance management in addition to gaining greater visibility as to where the market poses its stiffest challenges. More importantly, however, Base delivers a veritable library of customized analytics that illustrates a prominent use case for the convergence of cloud computing, real-time analytics and Big Data technologies. As such, the success of the platform will depend on its ability to continue enhancing its algorithms and analytics while concurrently enriching the user experience that remains integral to the daily experience of sales teams.
MapR Finalizes $110M In Equity And Debt Financing Led By Google Capital And Silicon Valley Bank
On Monday, MapR Technologies announced the finalization of $110M in funding based on $80M in equity financing and $30M in debt financing. Google Capital led the equity funding in collaboration with Qualcomm Incorporated, Lightspeed Venture Partners, Mayfield Fund, NEA and Redpoint Ventures while MapR’s debt funding was financed by Silicon Valley Bank. The funding will be used to spearhead MapR’s explosive growth in the Hadoop distribution and analytics space as illustrated by a threefold increase in bookings in Q1 of 2014 as compared to 2013. Gene Frantz, General Partner at Google Capital, commented on Google Capital’s participation in the June 30 funding raise as follows:
MapR helps companies around the world deploy Hadoop rapidly and reliably, generating significant business results. We led this round of funding because we believe MapR has a great solution for enterprise customers, and they’ve built a strong and growing business.
Monday’s announcement comes soon after MapR’s news of its support for Apache Hadoop 2.x and YARN in addition to all five components of Apache Spark, the open source technology used for big data applications that specialize in interactive analytics, real-time analytics, machine learning and stream processing. The additional $110M in funding strongly positions MapR with respect to competitors Cloudera and Hortonworks given that Cloudera recently raised $900M and Hortonworks finalized $100M in funding. The news of MapR’s $110M funding also coincides with a recent statement from Hortonworks certifying the compatibility of YARN with Apache Spark as part of a larger announcement about the integration of Spark into the Hortonworks Data Platform (HDP) alongside its Hadoop security acquisition XA Secure and Apache Ambari for the provisioning and management of Hadoop clusters. With a fresh round of capital in the bank and backing from Google, the creators of MapReduce, MapR signals that the battle for Hadoop market share features a three horse race that is almost certain to intensify as vendors compete to streamline and simplify the operationalization of Big Data. In the meantime, Big Data-related venture capital continues to flow like water bursting out of a fire hydrant as the Big Data space tackles problems related to big data analytics, streaming big data and Hadoop security.
Xplenty Expands Coverage to all Amazon Web Services’ Regions
PRESS RELEASE
Customers using Amazon CloudFront can now benefit from Xplenty to parse and process their log files, all within the Xplenty design environment
Tel Aviv, Israel – March 4, 2014 – Xplenty, http://www.xplenty.com, provider of the innovative Hadoop-as-a-service platform, Amazon Web Services (AWS) Technology Partner in the AWS Partner Network, and seller on the AWS Marketplace, now offers its big data processing technology directly to customers in all AWS Regions. Xplenty is now available to customers from AWS’ Regions in South America (Sao Paolo), Asia Pacific (Singapore), Asia Pacific (Sydney), and Asia Pacific (Tokyo). This adds to the existing Xplenty locations of U.S. East (N. Virginia), U.S. West (N. California and Oregon) and EU (Ireland).
Xplenty technology provides Hadoop processing on the cloud via a coding-free design environment, ensuring businesses can quickly and easily benefit from the opportunities offered by big data without having to invest in hardware, software or related personnel.
Meanwhile, users of the Amazon CloudFront content delivery network can now use Xplenty to analyze their log files. New predefined templates let users parse and process Amazon CloudFront logs easily. The processing engine transforms structured and semi-structured big data and easily scales to petabytes as data requirements grow, allowing companies to better understand their customers.
One company already using Xplenty to gain better insight to their customers is WalkMe. “We have customers from a wide range of industries and verticals – including banks, financial institutions, retail services, tourism, leading software vendors and more – all of which use WalkMe to simplify their customers’ online experience. By using Xplenty to break down our log files, we’re able to gain valuable insights into our customer needs and preferences,” says Nir Nahum, VP of R&D at WalkMe. “With the easy-to-use GUI, we just designate the file location for processing, and it automatically sets up the template and runs.”
Xplenty is available within the global AWS Marketplace to customers seeking to integrate a Hadoop-as-a-Service platform to solve their big data processing challenges.
“Big data is shaping the way companies of all sizes develop new products and identify new opportunities to increase their efficiency,” said Brian Matsubara, Head of Global Technology Alliances, Amazon Web Services. “By bringing their Big Data analysis tools to the AWS cloud, Xplenty is giving customers an innovative approach to solve their business challenges. Xplenty leverages the AWS global platform to provide scalable Big Data solutions to customers around the world.”
“As a cloud-based service provider, we offer organizations of any size the opportunity to learn more about their customers, further personalize their services, and increase their bottom lines, all by enabling their big data analyses,” says Yaniv Mor, co-founder and CEO of Xplenty. “Why shouldn’t everyone gain by using the data they are paying to store anyway?”
About Xplenty
Xplenty was founded by data professionals for data professionals to deliver on the promise of big data. Xplenty’s true big data solution provides ROI almost immediately by uncovering valuable business insights, translating into higher revenues and increased competitiveness. Xplenty delivers a coding-free, cloud-based Hadoop-as-a-Service platform that transforms structured, unstructured, and semi-structured data into useable information in the AWS, Rackspace and Softlayer environments. Our goal is to make Hadoop accessible and cost-effective for everybody. http://www.xplenty.com
Media Contact
Amy Kenigsberg
K2 Global Communications
amy@k2-gc.com
tel: +972-9-794-1681 (+2 GMT)
mobile: +972-524-761-341
U.S.: +1-913-440-4072 (+7 ET)
All product and company names herein may be trademarks of their registered owners.

You must be logged in to post a comment.