
Last week, Sencha announced details of ExtReact, a platform that enables React developers to create visually appealing, data-intensive web applications. ExtReact streamlines and simplifies the addition of impressive user interface components to SaaS applications by rendering available more than 115 user interface components. Developers can use ExtReact to manage keyboard navigation, focus management, layout and data management. ExtReact enables developers to quickly and efficiently create impressive user interface components such as customized menus, trees, tabs, grids, forms, calendars and data visualizations that are instantly compatible with a multitude of browsers and devices as illustrated below:
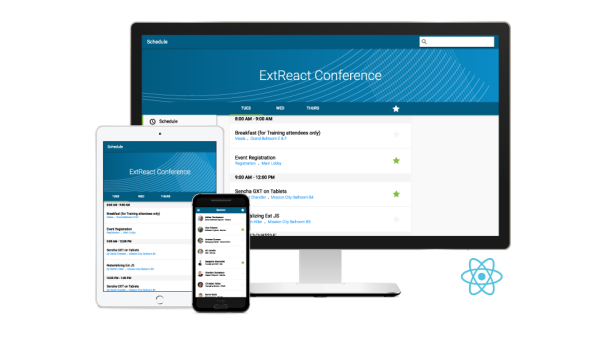
The availability of ExtReact enhances Sencha’s portfolio of tools for accelerating the development of data-intensive web applications. The company’s web application development platform empowers developers to focus on building their applications by taking advantage of Sencha’s pre-integrated, multi-valent library of UI components. Sencha’s multitude of platforms for designing, developing and testing components for web-based applications responds to the contemporary proliferation of data-intensive, web-based applications with rich data visualizations and aesthetically pleasing visual interfaces. ExtReact is expected to become generally available in Q2 of 2017.


You must be logged in to post a comment.